Edge AI on embedded devices spans three distinct tiers, each with different BOM, power, and engineering implications.
Everyone wants edge AI on their device. The board asks about it. Product wants it because competitors mention it. Marketing wants it for the press release.
Then the CTO has to figure out whether it’s actually worth doing, and what it costs in BOM, firmware complexity, timeline, and long-term maintenance.
We’ve had this conversation a dozen times in the past year. A client says “we want AI on the device.” Sometimes it makes sense. Sometimes it would add €8 to the BOM, 6 months to the timeline, and solve a problem that a well-tuned threshold algorithm handles just fine.
This is the decision framework we use internally when a client asks whether on-device inference is the right call for their product.
The Edge AI Spectrum Is Wider Than You Think
“Edge AI” covers everything from a €400 NVIDIA Jetson module to a €2 Cortex-M4. Conflating them is where bad decisions start.
Tier 1, Linux-class (€50–€400+ BOM, 5–60 W) Jetson, Qualcomm RB5, NXP i.MX 8M Plus. Millions of parameters. Computer vision at 30 FPS, multi-camera detection, NLP. Adds 6–12 months to your development timeline.
Tier 2, RTOS-class (€3–€15 BOM, 10–500 mW) STM32N6 (with Neural-ART NPU), Cortex-M55/M85, ESP32-S3. Hundreds of thousands of parameters. Keyword spotting, vibration anomaly detection, simple image classification. Adds 2–4 months.
Tier 3, TinyML (€1–€5 BOM, <10 mW) Cortex-M4, STM32 mainstream lines, Nordic nRF52840 / nRF54L15. Tens of thousands of parameters, INT8 quantized. Sensor fusion, gesture recognition, predictive triggers. Adds 6–12 weeks if the problem is well-scoped.
Most industrial and IoT teams are deciding between Tier 2 and Tier 3. That’s where this guide focuses.
Five Questions Before You Commit to Edge AI
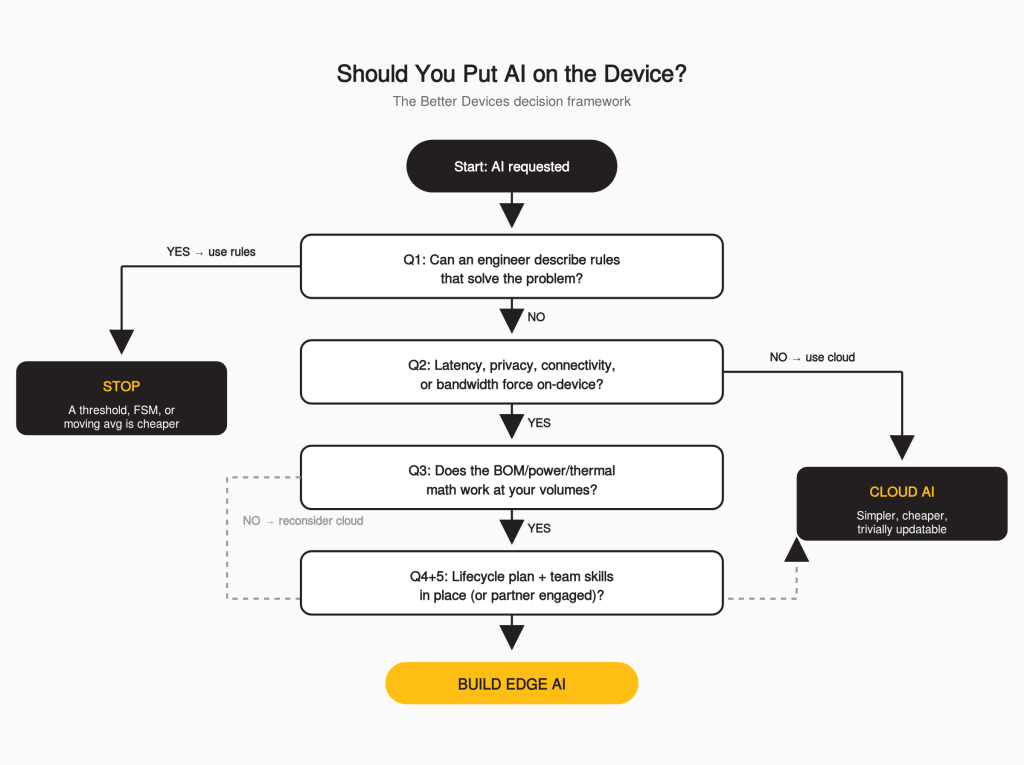
1. Does the problem actually require a learned model?
In our experience this kills more edge AI projects than any other single factor.
ML earns its place when the relationship between inputs and outputs is complex and hard to express in rules, vibration pattern recognition across multiple axes, visual defect detection with varied defect types, acoustic anomaly detection in variable environments.
ML is the wrong tool when a threshold, a moving average, or a state machine solves the problem. We’ve seen teams spend 4 months training a neural network for anomaly detection that a 3-sigma threshold on a moving average handled perfectly, running on a €0.50 MCU instead of a €12 one.
Our test: Can an experienced engineer describe rules that solve the problem with acceptable accuracy? If yes, you probably don’t need ML. If they say “I can see the pattern but can’t write the rules,” ML earns its place.
2. Does inference need to happen on-device?
On-device inference is justified when:
- Latency is critical, millisecond reaction times for safety or control loops
- Connectivity is unreliable, underground, offshore, inside metal enclosures
- Privacy demands it, medical signals, GDPR-sensitive audio/video, OEM data restrictions
- Bandwidth is expensive, raw sensor streams over LoRaWAN or NB-IoT aren’t viable
If none of these apply, reliable Wi-Fi, decision latency in minutes, non-sensitive data, cloud inference is simpler, cheaper, and far more maintainable. The firmware stays clean. The model is trivial to update. The BOM stays low.
The cost math: Cloud inference costs roughly €0.30–€3.00 per device per year at 100 inferences/day for lightweight sensor classification, and €30–€100 per device per year for vision-API workloads (Cloud Vision, Rekognition at roughly €0.001–€0.0015 per image). Adding edge AI capability adds €5–€15 per unit to the BOM. At 10,000 units, that’s €50,000–€150,000 upfront versus €3,000–€1,000,000 per year in cloud costs depending on workload. The math favours on-device at high volumes, high inference frequency, vision-heavy use cases, or when the conditions above make cloud impossible.

3. What’s the real BOM impact?
This is where enthusiasm meets physics.
MCU upgrade: Cortex-M4 → Cortex-M55 with Helium adds €3–€8. Moving to a Linux-class SoC with NPU adds €30–€200+.
Memory: A keyword spotting model needs ~250 KB flash and ~50 KB RAM. Visual anomaly detection typically needs 2–8 MB flash and 0.5–2 MB RAM depending on input resolution and architecture. If your current MCU doesn’t have headroom, you need a larger part or external memory.
Power: A Cortex-M55 running 10 inferences per second of around 10 ms each draws roughly 15 mW average, but peak power during each inference is closer to 100 mW.

If your total budget is 50 mW for a 3-year battery life, you’ve just allocated 30% of it to AI alone. That might mean a larger battery, more cost, more size, more weight.
Thermal: Tier 1 devices in sealed IP67 enclosures often need thermal management that wasn’t in the original design. We’ve seen projects where the thermal solution cost more than the compute module.
4. What’s the model lifecycle?
This is the question engineering teams forget and operations teams inherit.
Three types of drift are real, and each has different signals and mitigations:
- Data drift, input distributions shift (different sensor placement, different environment, different lighting)
- Concept drift, the input-output relationship itself changes (a defect type evolves, a failure mode mutates)
- Hardware drift, sensors age or component tolerances vary across production runs
Accuracy degrades silently in all three. You need monitoring, drift detection, and a retraining pipeline that addresses the right type for your deployment.
Redeployment is an OTA problem. Model updates are binary blob updates in flash. Your OTA architecture needs to support model-only updates without a full firmware reflash.
Validation is harder than testing. You can’t unit-test a model. You validate against a test dataset, but field performance can deviate significantly. You need telemetry that reports confidence scores so your data team knows when the model is struggling.
Long-term maintenance is a commitment. A model on an industrial device with a 10-year lifecycle isn’t “done” at launch. It’s a living component that may need multiple retraining cycles. This is an ongoing cost that rarely appears in the initial project estimate.
5. Does your team have the skills?
Edge AI on constrained devices requires embedded firmware engineering (memory management, RTOS, driver-level optimization) AND machine learning engineering (model architecture, quantization, training pipelines). Very few engineers are strong in both.
An edge AI feature scoped as “2 weeks of firmware work” by a team that doesn’t understand quantization or activation buffer sizing will take 2 months. Budget for the expertise gap explicitly, either through hiring or a partner engagement.
How to Execute an Edge AI Project in Five Steps
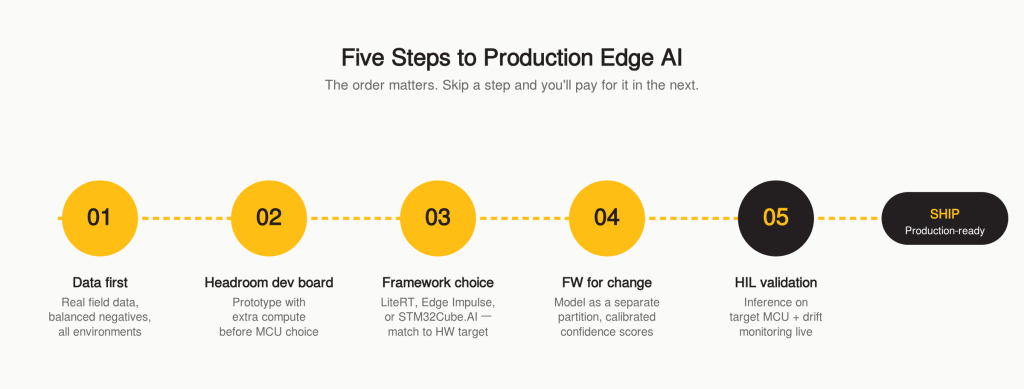
Step 1: Start with data, not models
Collect real sensor data from real devices in real operating conditions before you pick a framework. Not lab data. Field data, with all its noise. The dataset needs to cover every operating environment, every hardware revision, every failure mode you want to detect, plus a balanced set of negative examples. Most teams underestimate negative-example coverage by an order of magnitude. If you can’t collect a viable training dataset in 4 weeks, the timeline is already longer than your plan says.
Step 2: Prototype on a dev board with headroom
Don’t select your production MCU based on day-one model requirements, the model will change. Prototype on a dev board with more flash, RAM, and compute than you’ll need. Measure latency, accuracy, and power. Then optimize the model to fit your production target. Selecting the MCU first and squeezing the model onto it is how projects turn into 18-month optimization marathons.
Step 3: Choose your framework for deployment
For Tier 2/3 MCU targets, the practical options are LiteRT for Microcontrollers (formerly TensorFlow Lite Micro, most mature, widest hardware support), Edge Impulse (best end-to-end pipeline for teams without deep ML expertise), or STM32Cube.AI / ST Edge AI (strong STM32 integration, vendor lock-in, but the right call if you’re already committed to the STM32N6 or similar).
A note on CMSIS-NN: it’s not itself a deployment framework. It’s the optimized kernel library that LiteRT for Microcontrollers calls transparently on Cortex-M targets (including M4/M7, not just M55). You’ll use it whether you choose it or not. Treat it as a performance layer, not a framework decision.

Choose based on your hardware target and your team’s capability, not hype.
Step 4: Architect firmware for a model that will change
Treat the model as a replaceable component. Store it in its own flash partition for model-only OTA updates. Abstract the inference interface behind a generic function, run_inference(input, output), so swapping models doesn’t mean rewriting application code. Allocate memory statically at boot time. Build a confidence reporting mechanism so your application knows when to fall back to a rule-based approach, and calibrate those confidence scores using temperature scaling or isotonic regression on a held-out validation set. Raw softmax outputs after INT8 quantization are notoriously poorly calibrated and will trigger fallbacks incorrectly without calibration.
Step 5: Validate against reality
A model with high test-set accuracy can lose 10–20 percentage points in the field if the training distribution doesn’t cover deployment conditions. Run inference on the actual target MCU, quantization and fixed-point arithmetic change behaviour. Test against data from multiple deployment environments. Your HIL test bench should include an ML inference test path that catches accuracy degradation before units ship.
The Bottom Line
Edge AI is a powerful capability when it’s applied to the right problem with the right constraints. It’s an expensive distraction when it’s applied because “competitors are doing it” or “investors want to hear about AI.”
The decision isn’t technical, it’s economic. Does on-device inference create enough product value to justify the BOM increase, the development timeline, the firmware complexity, and the ongoing model maintenance? If the answer is clearly yes, the five-step execution framework gets you there without the 6-month detour. If the answer is ambiguous, start with cloud inference and a clean data pipeline. You can always move inference to the device later. Moving it off the device, after you’ve committed to the hardware, is much harder.
At Better Devices, we help engineering teams make this decision with real data instead of assumptions, and when edge AI is the right call, we design the firmware architecture, model integration, and testing infrastructure to get it to production. Book an edge AI feasibility review.
Join other engineering leaders receiving our monthly insights, or reach out to discuss how Better Devices can help your team ship faster.